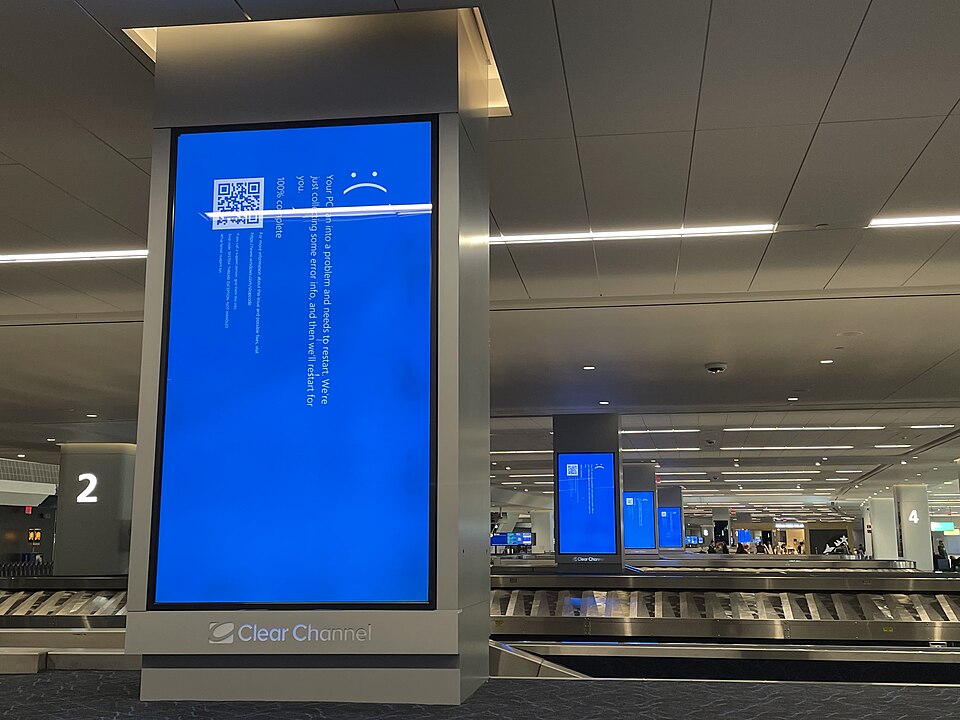
At 04:09 UTC on July 19, 2024, CrowdStrike's automated content delivery system pushed an update to every Windows machine running the Falcon sensor.
The update took 78 seconds to distribute.
By 04:17 UTC — eight minutes later — the first reports were appearing on CrowdStrike's support forums. Blue screens. Boot loops. Machines that could not start. Within the hour, it was clear this was not a local problem, not a bad batch of hardware, not a targeted attack.
It was everything.
Airports across the United States, Europe, and Australia froze. Delta, United, and American Airlines issued simultaneous ground stops. Surgeries were postponed in NHS hospitals across England. Emergency dispatch systems went offline in multiple U.S. states. Sky News went dark. Banks could not process transactions. Courts suspended operations.
8.5 million Windows machines. Blue screens. All of them, simultaneously.
The largest IT outage in recorded history had been caused by a single content file — not a cyberattack, not a hardware failure, not a software update in the traditional sense. Seventy-eight seconds of automated distribution. Days of manual recovery.
The Machine Inside the Machine
To understand how a single file destroyed global IT infrastructure for a day, you need to understand what CrowdStrike Falcon is and where it lives inside a Windows computer.
CrowdStrike Falcon is an endpoint detection and response platform used by roughly 60% of Fortune 500 companies, major government agencies, banks, airlines, and hospitals. Its job is to monitor every process running on a machine and identify malicious behaviour in real time.
To do that job, Falcon cannot sit at the application layer, where normal software runs. It has to sit deeper. Falcon runs at the kernel level — inside the Windows kernel itself, in the most privileged execution environment available on a modern computer.
This is not unusual for security software. A sophisticated threat — a rootkit, a kernel exploit, anything designed to evade detection — operates at the kernel level. To catch it, you have to operate there too. You have to see everything the operating system sees, before it can be hidden.
The component that does this is the Falcon sensor: a kernel driver named csagent.sys. It loads before most other processes, intercepts system calls, and watches for patterns that indicate malicious behaviour. Because it runs in kernel space, an unhandled exception doesn't crash just the Falcon software. An unhandled exception in csagent.sys crashes Windows. There is no isolation. There is no recovery. The operating system stops.
This architectural fact — the necessary architectural fact — is what turned a content file validation error into 8.5 million blue screens.
Channel Files: The Fast Lane With No Guard Rail
CrowdStrike Falcon relies on two distinct update mechanisms.
The first is the sensor itself: the csagent.sys kernel driver and associated software. These updates go through a full development and testing cycle. They are validated, staged, reviewed. They are infrequent and carefully controlled.
The second is channel files — also called rapid response content. These are not code updates. They are configuration and detection logic: definitions of what behavioural patterns to watch for, which processes to flag, how to respond to specific events. They look like data files. Their purpose is to allow CrowdStrike to update threat intelligence rapidly — sometimes multiple times per day — without requiring a full sensor deployment.
Because they were treated as data rather than software, channel files were subject to lighter validation than sensor updates. They did not go through the same testing pipeline. They could be pushed quickly. In the threat intelligence context, speed is the point.
Each channel file has a number. The file responsible for July 19 was channel file 291, stored as C-00000291-00000000-00000032.sys. Its role was to configure the Falcon sensor's handling of Inter-Process Communication — a Windows mechanism by which processes communicate with each other, and which malicious software frequently abuses.
The Bug: 21 Fields Where 20 Were Expected
The technical cause of the outage sits at the intersection of a content validation failure and a runtime assumption that was never questioned.
Channel file 291 contained template instances — structured definitions that told Falcon what IPC patterns to monitor. Each template instance had a specific number of input parameter fields that the sensor was designed to handle.
The July 19 update contained template instances with 21 fields. The Falcon sensor's runtime code expected 20.
When the sensor attempted to process the 21st field, it tried to read memory at an address that had not been allocated for that purpose. An out-of-bounds memory read. The value at that address was not a valid parameter — it was whatever happened to occupy that memory location. In most cases, a null pointer or uninitialised data.
The Falcon sensor code did not handle this gracefully. It attempted to dereference the pointer. Dereferencing a null or invalid pointer in kernel space does not produce an error that can be caught and handled. It produces a kernel panic.
Windows calls this a Stop error. Everyone else calls it a Blue Screen of Death.
The machine did not crash because of a security failure. It crashed because a bounds check on the content validator did not exist.
CrowdStrike's later analysis confirmed this: the Content Validator, a tool designed to verify channel files before deployment, contained its own defect. It did not detect the invalid field count. The malformed file passed validation. It was pushed.
Seventy-Eight Seconds
At 04:09 UTC, CrowdStrike's content delivery infrastructure began distributing the updated channel file 291 to every Windows machine running the Falcon sensor globally.
Falcon sensors are configured, by design, to pull updates automatically. This is a feature: threat intelligence that requires manual deployment is stale threat intelligence. Every endpoint updates continuously. Every endpoint is always running the latest content.
At 04:09 UTC, every endpoint became a target.
By 04:17 UTC — eight minutes after distribution began — the CrowdStrike support forums showed the first reports: machines in the United States and Europe were crashing. Blue screen. Boot. Blue screen. Boot.
At 05:27 UTC, CrowdStrike acknowledged the issue publicly. The post was brief. The cause was unknown. Customers were advised to await further guidance.
By that time, across time zones opening for business, the full scale of the outage was visible.
What It Looked Like on the Ground
Airports
At approximately 05:00 UTC, United Airlines, American Airlines, and Delta Air Lines issued simultaneous ground stops. The Federal Aviation Administration reported widespread IT system failures affecting airline operations. Flight crews couldn't access dispatch systems. Gate agents couldn't process boarding. Check-in kiosks showed blue screens.
Berlin Brandenburg Airport suspended check-in operations. Amsterdam Schiphol handled flights manually. Sydney Airport turned to paper. At Heathrow, Terminal 5 queues stretched hundreds of metres as automated systems failed.
Delta Air Lines' recovery was the worst in the industry. While other carriers restored systems within hours, Delta's deep integration of CrowdStrike-protected systems meant cancellations continued for five days. 7,000 flights cancelled. Approximately $500 million in losses. The U.S. Department of Transportation opened an investigation.
Hospitals
NHS England hospitals received an alert at approximately 06:00 UTC warning of a widespread IT system outage affecting clinical operations. Surgery theatres paused. Elective procedures were postponed. In hospitals where anaesthetic systems, patient monitoring, and electronic prescribing all ran on Windows endpoints protected by Falcon, the outage was not merely inconvenient — it was clinically dangerous.
Patients mid-preparation for procedures were sent home. Outpatient appointments were cancelled by the thousands. Clinical staff reverted to paper records in environments that had been entirely digital for years.
911
In at least six U.S. states — including Alaska, Ohio, and parts of Texas — emergency dispatch systems went offline. Dispatchers could receive calls but could not access the software that mapped call locations, assigned units, or tracked response status. Some centres diverted calls to neighbouring jurisdictions. Others operated on handwritten logs.
In Brewster County, Texas, the 911 centre lost all system access for three hours.
Broadcasting
Sky News went off air at approximately 06:30 UTC. Presenters and producers were unable to access broadcast systems. Viewers saw a holding screen. The channel was dark for most of the morning. Australia's ABC similarly reported production system failures. Broadcasters across Europe found newsroom systems offline at the start of the business day.
The Fix That Required a Human at Every Machine
By 09:22 UTC, CrowdStrike published a workaround. The instructions were specific and, for the scale of the problem, almost absurd in their manual requirements:
- Boot Windows into Safe Mode or the Windows Recovery Environment
- Navigate to
C:\Windows\System32\drivers\CrowdStrike\ - Locate the file matching
C-00000291*.sys - Delete it
- Reboot
For machines encrypted with BitLocker — which is to say, most enterprise machines — step zero was to retrieve the BitLocker recovery key from Active Directory or Azure AD. For IT teams managing thousands of endpoints, this was an hours-long process even with the key in hand.
There was no automated remediation. There was no remote fix. Every affected machine required someone — physically present or with console access — to execute five manual steps. For virtual machines, cloud snapshots provided a faster path. For physical desktops, laptops, point-of-sale terminals, and airport kiosks: physical access, one machine at a time.
Hospitals had machines embedded in medical equipment. Airlines had machines inside ticketing kiosks bolted to terminal floors. Banks had ATMs. Every organisation with physical infrastructure discovered, on July 19, that their endpoint security vendor's update process had no rollback mechanism, and their recovery plans had not been written for this scenario.
The Engineering Failures
The CrowdStrike outage was not a cyberattack. It was not sabotage. It was the predictable consequence of several specific engineering decisions converging on a single moment.
Rapid response content bypassed the validation standards applied to sensor updates.
Channel files could be deployed at speed because they were classified as data, not code. But data that is parsed by kernel-level code and directly influences its execution behaviour is not neutral data — it is effectively code. The Content Validator had its own defect, but the deeper failure was treating "data file" and "safe to deploy" as synonyms. Any configuration that can crash a kernel driver carries the same risk profile as a kernel driver update. It should carry the same validation requirements.
There was no staged rollout. No canary deployment. No gradual exposure.
The update was pushed to every online Falcon sensor simultaneously. Modern deployment practice requires controlled rollout: push to 1% of endpoints, observe, push to 10%, observe, push to 100%. A staged rollout of channel file 291 would have crashed a small subset of machines at 04:09 UTC. An engineer monitoring the rollout dashboard would have seen the crash rate spike. The rollout would have been halted. The remaining 99% of endpoints would have been spared.
CrowdStrike had no staged rollout for rapid response content. The speed that made the feature valuable made the failure global.
There was no automated rollback.
When an update causes a machine to crash on boot, the correct automated response is to boot the previous configuration. Consumer operating systems have done this for years. The Falcon sensor, running at kernel level on millions of critical infrastructure machines, had no equivalent. A crashed machine had no automatic path to recovery. It required manual intervention. The absence of rollback was not an oversight — it was a gap that had never been formally named as a risk.
The failure mode was known. The risk was accepted as the cost of kernel-level protection.
CrowdStrike engineers knew that a defective update to a kernel driver could crash Windows. That is why sensor updates were subject to rigorous testing. The decision to treat channel files differently — as fast-deployable data — was the gap between what was known and what was mitigated. The Knight Capital disaster illustrates the same logic: a flag that was "just data" pointing at code that nobody had audited caused $440 million in losses in 45 minutes. In both cases, the assumption that something was inert turned out to be wrong in the worst possible circumstances.
The Aftermath
CrowdStrike's stock fell 11% on July 19 — a loss of approximately $9 billion in market capitalisation in a single session. By the following week it had lost roughly 30% from its peak.
Delta Air Lines pursued legal action, seeking damages for the $500 million in losses and 7,000 cancelled flights. CrowdStrike disputed the characterisation that it bore sole responsibility.
The total insured loss was estimated by Parametrix, a cloud insurance firm, at $5.4 billion — with only 10 to 20% covered by cyber insurance policies. The uninsured exposure — business interruption, recovery costs, reputational damage — dwarfed the covered losses. The broader economic impact, including uninsured costs across all affected sectors, was estimated at more than $10 billion.
George Kurtz, CrowdStrike's CEO, appeared before the U.S. House Homeland Security Committee in September 2024. He described the Content Validator defect, the absence of staged rollout, and the changes CrowdStrike had implemented: multi-layer validation for channel file content, a staged deployment mechanism for rapid response updates, and enhanced in-sensor testing before content is applied.
The changes were real. They were also five months too late for the 8.5 million machines that crashed on a Friday morning.
What This Means for Anyone Who Builds Software
Data that controls execution is code. Validate it accordingly.
Channel file 291 was not code in the traditional sense. But it was parsed by a kernel driver, and its content directly determined what the kernel driver did. Treating it as inert data — subject to lighter validation, faster deployment, less scrutiny — was a category error. The validation burden on any configuration that can crash a kernel driver should be identical to the validation burden on the driver itself. If you cannot make that fast, you change what "fast" means for that content type.
Staged rollout is not optional for infrastructure that runs at kernel level.
When a defect in your deployment can crash 8.5 million machines simultaneously, the question is not whether to stage the rollout. The question is how small to make the first stage. The blast radius determines the answer. When the blast radius is "the entire global customer base plus critical infrastructure in 80 countries," the answer is: very, very small, with automated halt criteria and human sign-off between stages.
The absence of automated rollback is a design decision. Name it as one.
Every system that deploys configuration to endpoints should be designed with the assumption that the configuration will sometimes be wrong. Rollback should be automatic: if the endpoint crashes after applying an update, the next boot uses the previous configuration. This is not a complex feature. It is a basic requirement for systems where a failed update leaves the endpoint unbootable. Somewhere in CrowdStrike's architecture, a decision was made — implicitly or explicitly — that channel file rollback was not worth building. On July 19, 2024, that decision cost the global economy more than $10 billion.
Every fast path is a risk path. Speed without validation is a loaded weapon.
Rapid response content existed because threat intelligence has a half-life. A detection rule that takes a week to deploy is useless against an active zero-day. The speed had genuine value. But every fast path that bypasses safety controls is simultaneously a fast path for defects. The same delivery infrastructure that got legitimate threat intelligence to 8.5 million endpoints in 78 seconds got a kernel-crashing file to those same endpoints in 78 seconds. Speed without validation is not a feature. It is a delivery system for failures at unprecedented scale.
Recovery plans must be tested against the scenarios they will actually face.
Organisations that spent the morning of July 19 discovering that their BitLocker recovery keys were not accessible, that their physical endpoints had no remote management path, and that their disaster recovery runbooks did not cover "endpoint security vendor pushes a kernel crash to all machines simultaneously" — those organisations had recovery plans. The plans just hadn't been tested against this. The CrowdStrike outage was an event type most enterprise IT teams had never modelled. After July 19, 2024, it is a scenario everyone has.
When your product runs at kernel level on critical infrastructure, your update process is itself critical infrastructure.
CrowdStrike's customers extended the deepest trust possible: access to the kernel of every machine in their estate. That trust created an obligation that extended beyond detecting threats — it extended to the entire lifecycle of every update pushed through that access. The update process was not treated as critical infrastructure. It should have been. The lesson is not specific to CrowdStrike. It applies to every vendor whose software runs with elevated privilege on machines that cannot afford to be offline.
Go Deeper
To understand what happened:
- CrowdStrike's Preliminary Post Incident Review (July 24, 2024) — free and public, technically detailed account of the channel file 291 failure
- CrowdStrike's Root Cause Analysis (August 6, 2024) — the follow-up with full technical analysis of the Content Validator defect
- George Kurtz's testimony before the House Homeland Security Committee (September 24, 2024) — the public record of what CrowdStrike said under oath
To understand how to prevent it:
- "Release It!" by Michael Nygard — the foundational text on designing systems that fail safely and recover automatically
- "Site Reliability Engineering" by Beyer, Jones, Petoff, and Murphy (the Google SRE book) — on safe deployment practices, canary releases, and progressive rollout at scale
- "Accelerate" by Nicole Forsgren, Jez Humble, and Gene Kim — on the engineering practices that distinguish resilient deployment pipelines from fragile ones
To understand the systemic pattern:
- "Normal Accidents" by Charles Perrow — why tightly coupled systems produce failures that are structurally difficult to prevent without specific design choices
- Postmortem analyses of the 2021 Facebook outage and the 2022 AWS us-east-1 disruption — different mechanisms, the same structural lesson about single points of failure in update and configuration pipelines
The series starts with Therac-25 — the race condition that turned a radiation machine into a weapon.
Sources:
- CrowdStrike. Preliminary Post Incident Review: Falcon Content Update for Windows Hosts. July 24, 2024.
- CrowdStrike. Root Cause Analysis — Channel File 291 Incident. August 6, 2024.
- U.S. House Homeland Security Committee. Hearing: CrowdStrike's Faulty Update: Lessons Learned. September 24, 2024.
- Parametrix. Cyber Market Insights: CrowdStrike Outage Analysis. July 2024.
- U.S. Department of Transportation. Statement on Delta Air Lines' handling of the CrowdStrike IT outage. July 2024.
- The Verge. "The CrowdStrike update that broke the world." July 19, 2024.
- Wired. "CrowdStrike Blames a Bug in Its Own Software for the Massive Windows Outage." July 20, 2024.
- Reuters. "CrowdStrike chaos could cost US companies $5.4 billion: Parametrix." July 24, 2024.